近日,宋敏教授团队在国际知名期刊《Chip》上发表题为“SOT-MRAM based true in-memory computing architecture for approximate multiplication”的研究论文。该成果基于单极性翻转SOT-MRAM(自旋轨道矩磁阻存储器),提出了一种在存储阵列内实现近似乘法的真存内计算架构的新路径。

传统计算中,「内存墙」—处理器与内存之间频繁的数据搬运—成为性能与能效的瓶颈。在本工作中,研究者提出了一种基于单极自旋轨道矩磁阻存储器 (SOTMRAM)器件(图1a)的真存内计算架构—STIMC(图1d)。该架构通过优化计算步骤有效加速逻辑运算,实现可重构逻辑门(图2a),并基于此构建了高效的1比特全加器(图2b)和n比特行波进位加法器(图2c)。同时将大部分中间计算结果存储在存储阵列中,从而最小化内存与处理器间的通信。
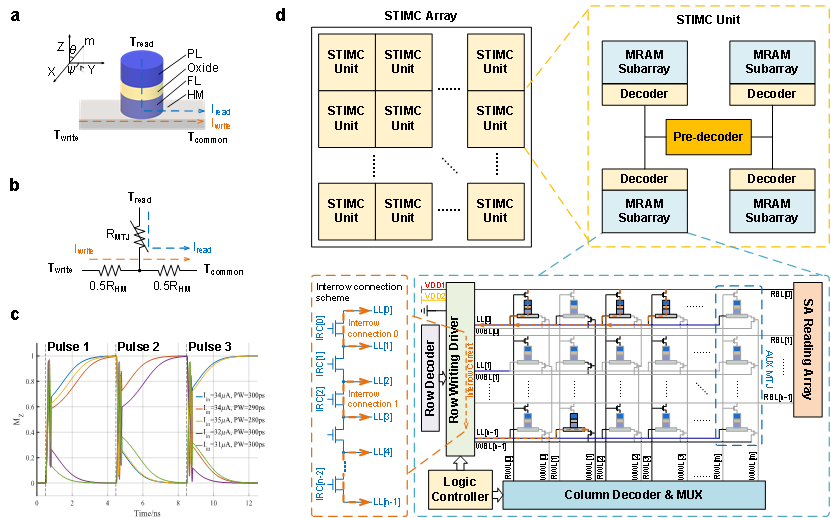
图1 | STIMC各层级架构。a(单极SOT-MRAM结构);b(SOT-MRAM等效电路);c(单极器件翻转特性);d(STIMC计算架构)。
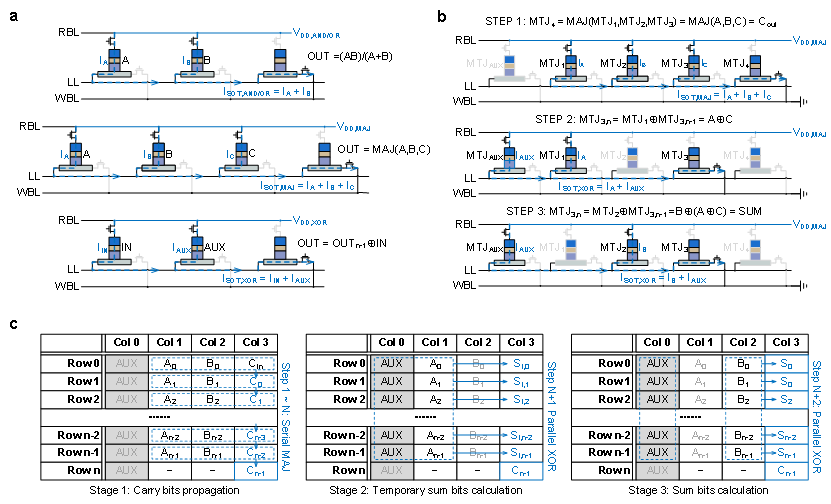
图2 | STIMC架构实现的存内数字计算电路。a(自旋逻辑门原理图:或/与门、多数门以及异或门);b(基于多数门与异或门的全加器);c(n位自旋行波进位加法器的映射示意图与运算流程)。
团队设计了两种基于多数逻辑门的近似压缩器,通过在相反方向生成误差以实现误差累积的平衡,并将其应用于8×8近似乘法器中,如图3所示。除此以外,将该乘法器完整映射至2T+1M单元的存储阵列中,采用分区映射策略,在不同阵列之间并行协作,提高计算效率。
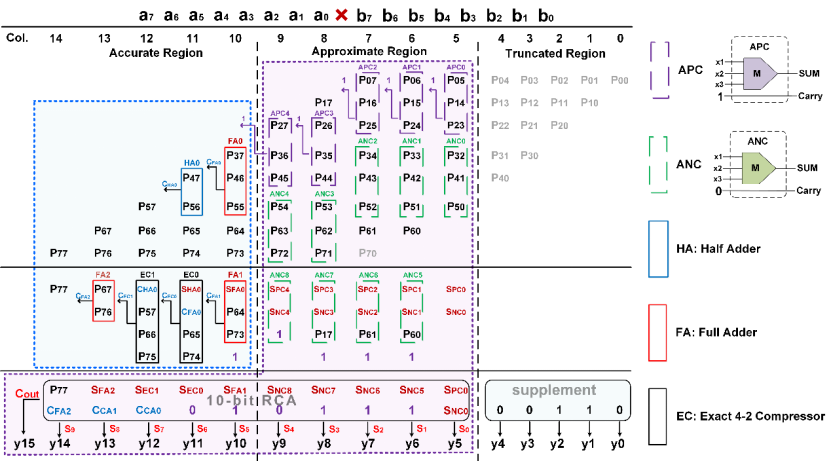
图3 | 基于压缩策略的8×8近似乘法器。
仿真结果表明,STIMC近似乘法器相比已报道设计3-5可实现74.2%的能耗下降和44.4%的延迟降低。将近似乘法器应用于图像平滑,可达到PSNR > 39 dB、SSIM > 0.95,在成本大幅降低的同时保持高质量输出。
该研究证明,基于SOT-MRAM的全电驱动真内存近似计算架构可兼顾性能与能效,特别适合容错型应用。通过将近似计算策略与存储器硬件深度融合,STIMC为人工智能、信号处理等领域的新一代加速器研发提供了极具潜力的解决方案。
本研究论文的第一作者为湖北大学微电子学院宋敏老师,通讯作者为华中科技大学游龙教授。Chip是全球唯一聚焦芯片类研究的综合性国际期刊,已入选中国科技期刊卓越行动计划高起点新刊项目、中国科技期刊卓越行动计划二期项目-英文梯队期刊,为科技部鼓励发表三类高质量论文期刊之一。(审稿人:游龙)

